hadoop3.x 统计词频案例(hadoop-mapreduce-examples)和web管理页面 作者:马育民 • 2021-02-09 22:34 • 阅读:10226 # 介绍 mapreduce提供的案例,可以统计某目录下 文件中的词频 # 准备工作 ### 启动服务 必须启动 hdfs 和 yarn ``` start-dfs.sh ``` ``` start-yarn.sh ``` ### 创建 文本文件 **注意:** 要保存为 `utf-8` 编码,否则生成 **结果文件是乱码** 创建文件 `/program/data.txt` ``` vim /program/data.txt ``` 内容如下: ``` 李雷 韩梅梅 lucy lili 张三 李四 王五 李雷 韩梅梅 lucy 李雷 韩梅梅 李雷 ``` 保存退出: 【esc】 ``` :wq ``` ### 创建目录 ``` hadoop fs -mkdir /data ``` ### 上传 ``` hadoop fs -put /program/data.txt /data ``` 将 linux 系统的 `/data.txt` 文件,上传到 HDFS `/data` 路径 # 案例命令 ``` hadoop jar /program/hadoop-3.0.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /data /result ``` **解释:** - `hadoop jar`:执行jar命令 - `/devtools/hadoop-3.0.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar`:jar包所在位置,可以是相对路径 - `wordcount`:统计词频。还有其他功能 - `/top/malaoshi/data`:读取 hdfs 的目录 - `/result`:将结果输出到 hdfs 的目录下 # 命令查看结果 ``` hadoop fs -cat /result/p* ``` 显示结果如下: ``` li 1 lucy 1 张三 1 李四 1 李雷 3 王五 1 韩梅梅 2 ``` **注意:** 此处可能是 **中文乱码**,原因:`data.txt` 没有保存为 `utf-8` 编码 # Hadoop web查看结果 访问 http://hadoop1:9870/ [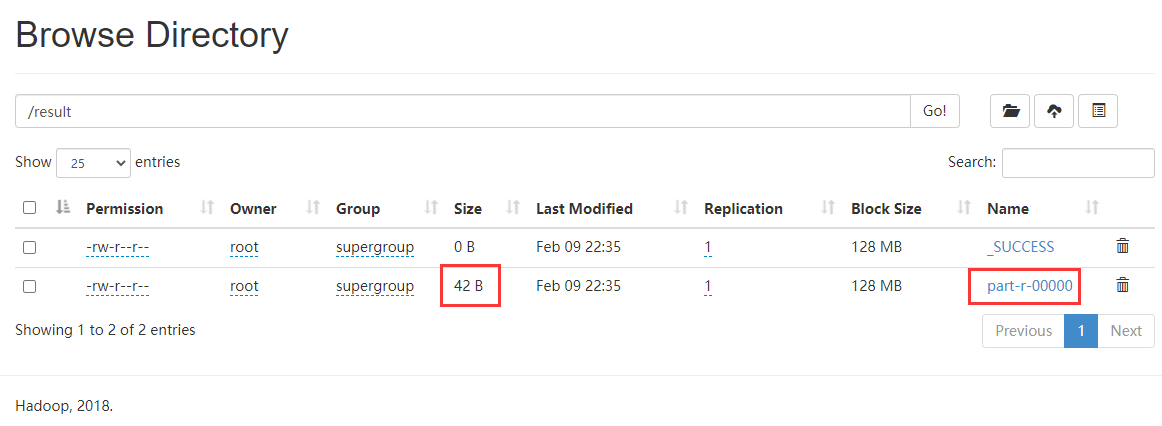](http://65242847.gitee.io/pic/hadoop/QQ20210209224800.png) # Yarn Web管理界面查看结果 访问:http://hadoop1:8088/ ,显示界面如下: [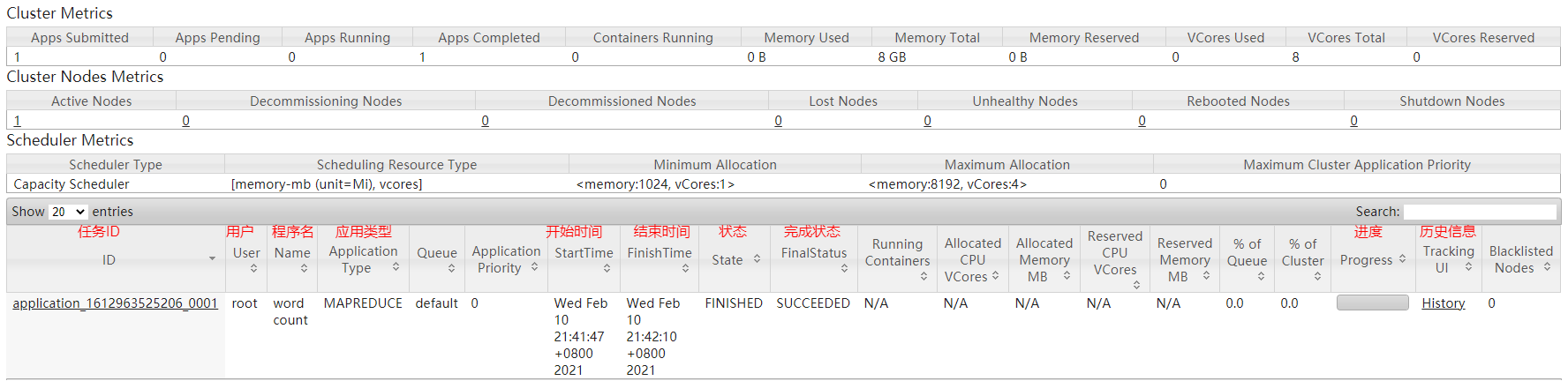](http://65242847.gitee.io/pic/hadoop/QQ20210210214302.png) 原文出处:http://malaoshi.top/show_1IXYw3PNLDQ.html