flink1.12.x:session cluster模式-测试wordcount 作者:马育民 • 2021-12-23 19:21 • 阅读:10315 # 注意 需要启动 yarn,命令如下: ``` /program/bin/hadoop.sh start ``` # 说明 在 flink 的 examples 目录下,都是一些官方的例子,如:WordCount.jar,读取一个文件,计算 wordcount,然后将结果保存到另一个文件中 # 准备文件 创建文本文件,内容如下: ``` 李雷 lucy 韩梅梅 lili lucy 李雷 lili 张三 张三 李四 王五 李雷 韩梅梅 lucy 李雷 韩梅梅 李雷 ``` 将其上传到 hdfs 的 `/test2` 目录下 # 启动 yarn-session ``` cd /program/flink-1.12.5 ``` ``` bin/yarn-session.sh ``` 或者 后台执行 ``` bin/yarn-session.sh -d ``` 执行结果如下: [](https://www.malaoshi.top/upload/pic/flink/Snipaste_2021-12-23_19-26-50.png) 看到上面红框处,说明启动成功 ### flink web ui 访问 http://hadoop1:43347 可查看 web ui [](https://www.malaoshi.top/upload/pic/flink/Snipaste_2021-12-23_19-28-47.png) ### yarn web ui 访问:http://hadoop2:8088/ 查看 yarn web ui # 提交任务 如下: ``` bin/flink run /program/flink-1.12.5/examples/batch/WordCount.jar --input hdfs://hadoop1:8020/test2/data.txt --output hdfs://hadoop1:8020/flink_result8 ``` **解释:** - `--input`:要读取的文件路径 - `--output`:要保存结果的文件 ### flink web ui 访问 http://hadoop1:43347 可查看 web ui [](https://www.malaoshi.top/upload/pic/flink/Snipaste_2021-12-23_19-38-50.png) # 查看结果 访问 HDFS:http://hadoop1:9870/ ,如下图: [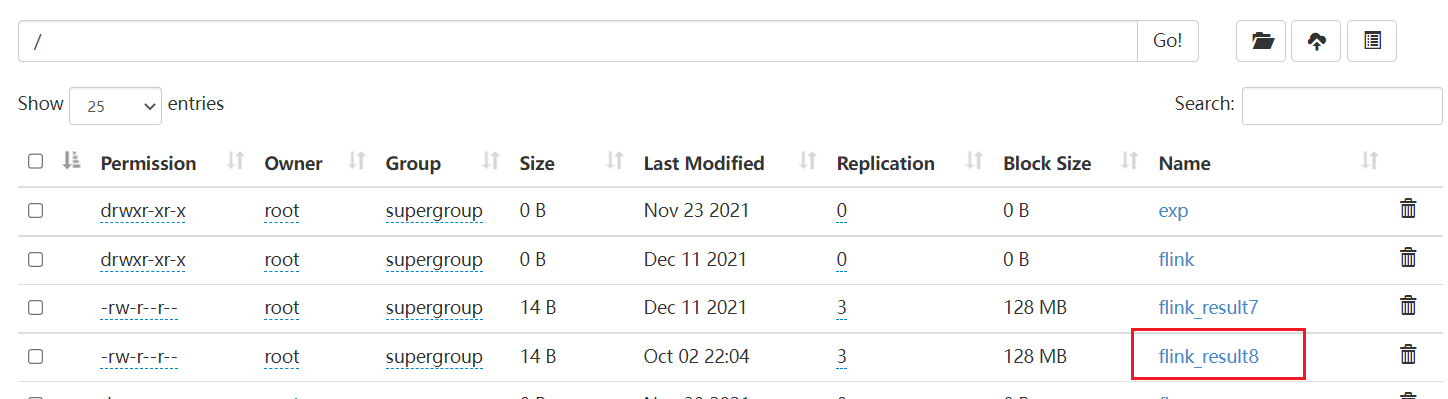](/upload/0/0/1IX49kJzyW0K.png) 文件内容如下: ``` lili 1 lucy 2 ``` 原文出处:http://malaoshi.top/show_1IX2Sc2JODEG.html