hadoop3.x yarn 调度策略:Fair Scheduler(公平调度)根据linux登录名创建队列 作者:马育民 • 2022-01-05 15:19 • 阅读:10136 # 说明 提交任务时,根据当前 linux 用户名,作为队列名,多个任务可同时执行 # 修改yarn-site.xml配置 登录 `hadoop2` ### 先备份 文件 `yarn-site.xml` 非常重要,防止改坏了,不容易恢复 ``` cp yarn-site.xml yarn-site.xml.bak ``` ### 开始修改 修改 `yarn-site.xml` 文件: ``` vim /program/hadoop-3.0.3/etc/hadoop/yarn-site.xml ``` 增加下面内容: ### 指定公平调度方式 ``` <!-- 指定使用fairScheduler的调度方式 --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> ``` ### 开启抢占 ``` <!-- 开启资源抢占,当队列资源使用 yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源,默认为false,即:不抢占 --> <property> <name>yarn.scheduler.fair.preemption</name> <value>true</value> </property> <property> <name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name> <value>0.8f</value> </property> ``` ### 删除下面配置 没有就忽略 ``` <!-- 指定配置文件路径 --> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>fair-scheduler.xml</value> </property> ``` ### 不要有 `fair-scheduler.xml` 文件(重要) `hadoop1`、`hadoop2`、`hadoop3` 的 `/program/hadoop-3.0.3/etc/hadoop/` 目录下 **不要有** `fair-scheduler.xml` 文件,否则会 **自动加载该文件**,**使配置受影响**,可能导致无法同时运行多个任务 # 同步 同步到 hadoop1: ``` rsync -av /program/hadoop-3.0.3/etc/hadoop/* root@hadoop1:/program/hadoop-3.0.3/etc/hadoop/ ``` 同步到 hadoop3: ``` rsync -av /program/hadoop-3.0.3/etc/hadoop/* root@hadoop3:/program/hadoop-3.0.3/etc/hadoop/ ``` # 重启 yarn 登录 `hadoop2`,执行下面命令关闭 yarn: ``` stop-yarn.sh ``` ``` start-yarn.sh ``` # 访问 web 访问:http://hadoop2:8088/ ,查看队列,显示界面如下: [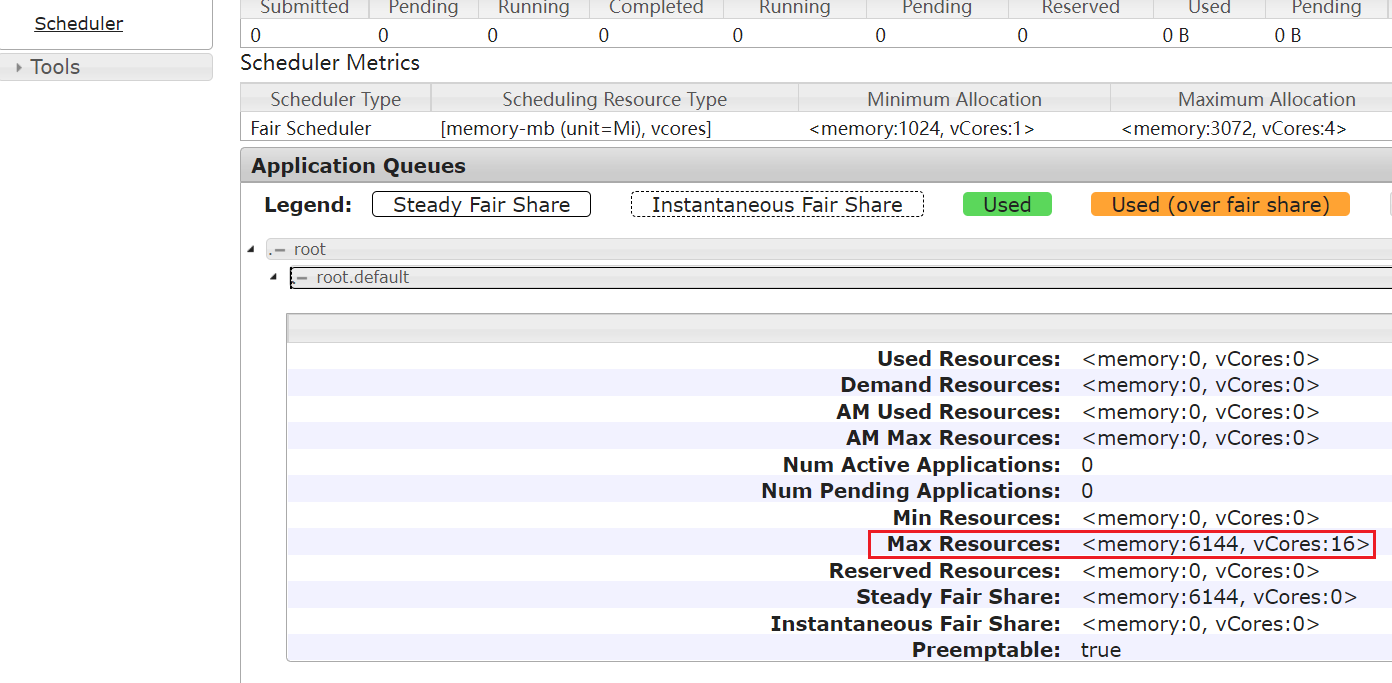](/upload/0/0/1IX49lah3sNF.png) 默认有 队列 `root.default` 最大资源:`6144mb内存`( `1024 * 6` )、`16` 个核心 # 测试 **同时** 在 hadoop1、hadoop3执行下面命令 ``` hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /test2/data.txt /result010519 ``` **参数解释:** - `/test2/data.txt`:读取 HDFS 文件 - `/result010519`:将结果写入到 HDFS上 ``` hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /test2/data.txt /result010518 ``` ### web查看任务 如下图,会发现多个任务同时执行 [](https://www.malaoshi.top/upload/pic/hadoop/Snipaste_2022-01-05_16-25-38.png) ### web查看队列 [](https://www.malaoshi.top/upload/pic/hadoop/Snipaste_2022-01-05_16-28-27.png) 会发现多出一个 `root.root` 队列,解释: - 第一个 `root`:表示根 - 第二个 `root`:因为 fair公平调度,提交任务未指定队列时,默认是将 **当前linux登录用户名作为队列名**,而当前 linux登录名是 `root` 此功能实现了根据 **用户名** 自动 **分配队列** 原文出处:http://malaoshi.top/show_1IX2XOQnuRNB.html