hadoop3.x yarn 调度策略:Fair Scheduler(公平调度)根据linux登录名提交到队列 作者:马育民 • 2022-01-05 15:48 • 阅读:10344 # 修改yarn-site.xml配置 登录 `hadoop2` 修改 `yarn-site.xml` 文件: ``` vim /program/hadoop-3.0.3/etc/hadoop/yarn-site.xml ``` 增加下面内容: ### 指定公平调度方式 ``` <!-- 指定使用fairScheduler的调度方式 --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> ``` ### 指定配置文件路径 ``` <!-- 指定配置文件路径 --> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>fair-scheduler.xml</value> </property> ``` **解释:** - 默认是 `$HADOOP_HOME/etc/hadoop/` 路径,也可以写全路径 - 默认文件名是:`fair-scheduler.xml` - 也就是说,如果文件路径是:`$HADOOP_HOME/etc/hadoop/fair-scheduler.xml` ,即使不写上面配置,也会自动加载该文件 **提示:** `yarn.scheduler.fair.allocation.file` 指定的文件每隔 10秒 加载一次,所以修改此文件,不需要重启 yarn ### 指定 虚拟内存和物理内存比例 虚拟内存的比例,默认是 `2.1`,即每使用 `1G` 物理内存,分配 `2.1` 的虚拟内存。 虚拟内存不够也会报oom,在nodemanager的日志中可以看到。 ``` <!--虚拟内存和物理内存设置比例,默认2.1--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> ``` ### 开启抢占 ``` <!-- 开启资源抢占,当队列资源使用 yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源,默认为false,即:不抢占 --> <property> <name>yarn.scheduler.fair.preemption</name> <value>true</value> </property> <property> <name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name> <value>0.8f</value> </property> ``` ### linux用户名作为队列名 ``` <property> <name>yarn.scheduler.fair.user-as-default-queue</name> <value>true</value> </property> ``` **解释:** - 默认true,提交任务未指定队列时,默认是将当前 **linux登录用户名** 作为队列名。可实现根据用户名自动分配队列 - 设置成false,当任务中未指定资源池的时候,将使用默认的队列,即:`root.default`,可在 `fair-scheduler.xml` 中配置默认队列 ### 禁止创建未定义的队列 ``` <property> <name>yarn.scheduler.fair.allow-undeclared-pools</name> <value>false</value> </property> ``` **解释:** - 默认为true,如果提交任务时指定 **没有** 的队列,会 **自动创建** 该队列。 - 设置为false,提交任务时应该指定 **已有** 的队列,如果指定的队列不存在,就会提交到 `root.default` 队列中 ### yarn.scheduler.fair.user-as-default-queue 和 yarn.scheduler.fair.allow-undeclared-pools 的关系 - 如果 `yarn.scheduler.fair.allow-undeclared-pools = true` ,`yarn.scheduler.fair.user-as-default-queue = true`,用 **linux登录用户名** 作为队列名,如果没有该队列,就会创建该队列(一般不这么操作) - 如果 `yarn.scheduler.fair.allow-undeclared-pools = false`,`yarn.scheduler.fair.user-as-default-queue = true`,用 **linux登录用户名** 作为队列名,那么: - 如果 **有 该队列**,会将该任务分配到 **该队列** - 如果 **没有 该队列**,会将该任务分配到 **默认队列**,一般为:`root.default` ### 关键 关键 关键 关键 不要有下面配置,如果有,要删除掉 或 注释掉: ``` <!-- nodemanager最大可用内存,不要超过物理内存 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>3072</value> </property> ``` 此配置会影响 公平调度器 队列内存,所以不要有该配置,详见 [链接](https://www.malaoshi.top/show_1IX4AUUdB8ST.html "链接") # 修改fair-scheduler.xml配置 新建 `fair-scheduler.xml` 文件: ``` vim /program/hadoop-3.0.3/etc/hadoop/fair-scheduler.xml ``` 内容如下: ``` <?xml version="1.0"?> <allocations> <!-- 定义根队列,所有队列都是root队列的子队列 --> <queue name="root"> <!-- 全局配置 --> <!-- 最小使用资源:2G内存,2个处理器核心 --> <minResources>2048mb,1vcores</minResources> <!-- 最大使用资源:4G内存,2个处理器核心 --> <maxResources>8192mb,4vcores</maxResources> <!-- 最大可同时运行的app数量:100--> <maxRunningApps>10</maxRunningApps> <!-- weight:资源池权重 --> <weight>1.0</weight> <!-- 调度模式:fair-scheduler --> <schedulingMode>fair</schedulingMode> <!-- 允许提交任务的用户名和组,格式为:用户名 用户组 --> <!-- 当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组 --> <aclSubmitApps> </aclSubmitApps> <!-- 允许管理任务的用户名和组,格式同上 --> <aclAdministerApps> </aclAdministerApps> <!-- 当提交的任务没有指定队列时,都提交到该队列中 --> <queue name="default"> <!-- 该队列的局部配置 --> <minResources>2048mb,1vcores</minResources> <maxResources>8192mb,4vcores</maxResources> <maxRunningApps>5</maxRunningApps> <!-- 队列内部使用公平调度,也可以是fifo --> <schedulingMode>fair</schedulingMode> <!-- 权重,按照该比例抢夺资源 --> <weight>2.0</weight> <!-- 允许提交任务的用户名和组,格式为:用户名 用户组(只写用户名也行) --> <!-- 当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组 --> <!-- *表示所有用户都可以运行 --> <aclSubmitApps>*</aclSubmitApps> </queue> <queue name="dev"> <minResources>2048mb,1vcores</minResources> <maxResources>8192mb,4vcores</maxResources> <maxRunningApps>10</maxRunningApps> <schedulingMode>fair</schedulingMode> <weight>1.0</weight> <!-- 允许提交任务的用户名和组 --> <aclSubmitApps>dev,flink</aclSubmitApps> <!-- 允许管理任务的用户名和组 --> <aclAdministerApps>dev,flink</aclAdministerApps> </queue> <queue name="test"> <minResources>2048mb,1vcores</minResources> <maxResources>8192mb,4vcores</maxResources> <maxRunningApps>5</maxRunningApps> <schedulingMode>fair</schedulingMode> <weight>1.0</weight> <!-- 允许提交任务的用户名和组 --> <aclSubmitApps>test</aclSubmitApps> <!-- 允许管理任务的用户名和组 --> <aclAdministerApps>test</aclAdministerApps> </queue> </queue> </allocations> ``` **解释:** - 全局配置:全局配置可以没有。其作用是:当队列配置项没有,但全局配置有此项,那么该队列就取该全局配置项 - 内存、核心:设置的最大资源是:`8192mb` 内存,`4个` 核心,但虚拟机 物理内存只有 `8G`,也就是说不是真的的物理内存(这里设置20G也可以生效) - weight:权重,资源不够,抢占资源时,按照比例进行分配 **注意:** - `<aclSubmitApps> </aclSubmitApps>`、`<aclAdministerApps> </aclAdministerApps>`如果是空,必须有空格,否则报空指针错 - 队列名 与 `aclSubmitApps` 名,linux用户要同名 ### 并发执行任务 的数量 执行 mapreduce 自带的 wordcount 时,需要的 **最小资源** 是 `2048mb` 内存 和 `1个` 核心,所以 **理论上** 最多能 **同时运行 `4个`** wordcount 程序。 **但实际上**,最多只能 **同时运行 `2个`** wordcount 程序,因为 **AM也需要内存** #### 注意 由于上面原因,运行一些程序(hive、spark、flink 等),如果没有指定运行内存,可能最多只能 **同时运行 `2个`** 程序 # 同步 登录 `hadoop2`,执行下面命令 同步配置文件: 同步到 hadoop1: ``` rsync -av /program/hadoop-3.0.3/etc/hadoop/* root@hadoop1:/program/hadoop-3.0.3/etc/hadoop/ ``` 同步到 hadoop3: ``` rsync -av /program/hadoop-3.0.3/etc/hadoop/* root@hadoop3:/program/hadoop-3.0.3/etc/hadoop/ ``` # 重启 yarn 登录 `hadoop2`,执行下面命令关闭 yarn: ``` stop-yarn.sh ``` ``` start-yarn.sh ``` # web 查看队列 访问:http://hadoop2:8088/ ,查看队列,显示界面如下: [](https://www.malaoshi.top/upload/pic/hadoop/Snipaste_2022-01-05_23-25-34.png) 可以看到队列 `root.default`、`root.dev`、`root.spark` [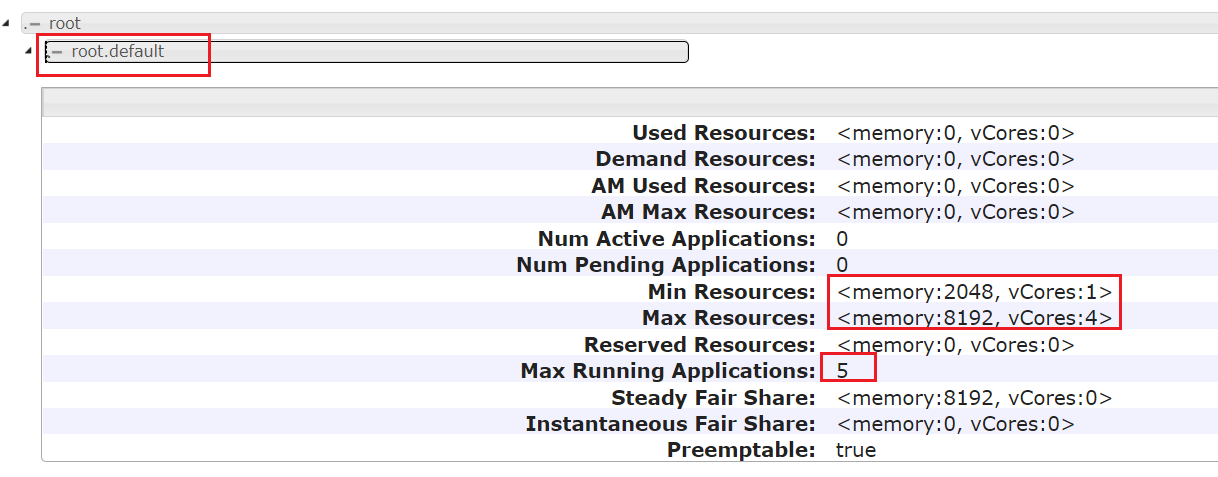](/upload/0/0/1IX4AVLNTopr.png) 可以看到配置项已生效 # 测试1 **同时** 在 `hadoop1`、`hadoop2`、`hadoop3` 执行下面命令: ### hadoop1 运行命令 ``` hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /test2/data.txt /yarn_result/1 ``` **参数解释:** - `/test2/data.txt`:读取 HDFS 文件 - `/result-1`:将结果写入到 HDFS上 ### hadoop2 运行命令 ``` hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /test2/data.txt /yarn_result/2 ``` ### hadoop3 运行命令 ``` hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount /test2/data.txt /yarn_result/3 ``` # 访问 yarn http://hadoop2:8088/cluster/apps 可以看到 **同时只运行 2个 程序**,有 **1个 程序在等待分配资源**,如下图: [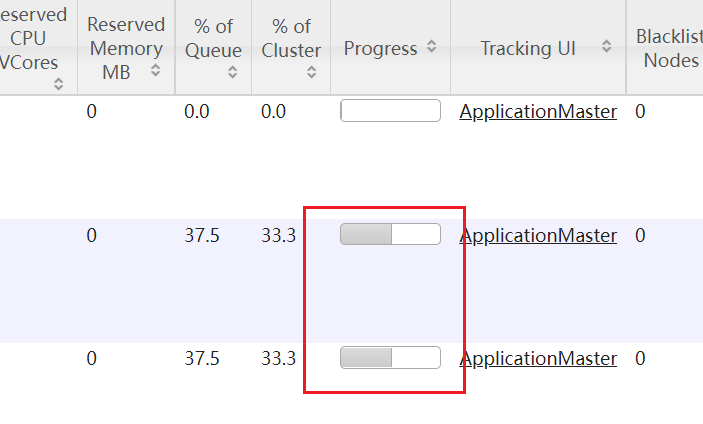](/upload/0/0/1IX49iCavI6k.png) ### 查看队列 [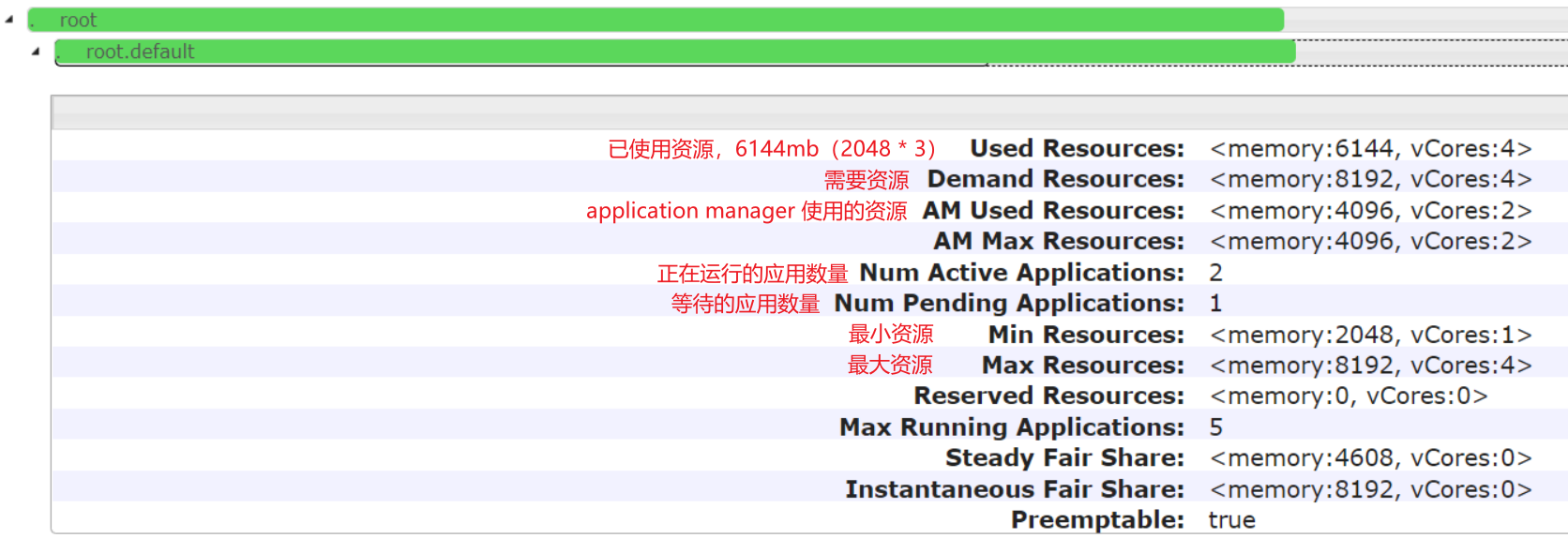](/upload/0/0/1IX49iSUqIzQ.png) 启动 MapReduce时,没有指定 队列,默认提交到 `root.default` 中 # 测试2 使用 spark 用户提交应用,以用户名作为队列名,自动提交到 `root.spark` 队列 ### 创建用户 必须在 hdfs服务器(即:hadoop1)上 创建 `spark` 用户,并指定 `supergroup` 用户组(因为是 HDFS的超级用户组),还要刷新 hdfs 用户、用户组映射 创建用户: ``` useradd spark ``` 设置密码: ``` passwd spark ``` 创建 `supergroup` 组(因为 HDFS 默认用户组就是`supergroup`): ``` groupadd supergroup ``` 将 `spark` 用户追加到 `supergroup` 组 ``` usermod -a -G supergroup spark ``` 刷新 hdfs 用户、用户组映射 ``` hdfs dfsadmin -refreshUserToGroupsMappings ``` 执行结果: ``` Refresh user to groups mapping successful ``` ### 在 hdfs服务器(hadoop1) 测试 切换 `spark` 用户: ``` su spark ``` 执行命令: ``` yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 2 2 ``` 访问:http://hadoop2:8088/ ,可以看到提交到 `root.spark` 队列 ### 在 非hdfs服务器(hadoop1) 测试 所在机器必须有 spark 用户,不需要有 `supergroup` 组 执行下面命令创建用户: ``` useradd spark ``` 切换 `spark` 用户: ``` su spark ``` 执行命令: ``` yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 2 2 ``` 访问:http://hadoop2:8088/ ,可以看到提交到 `root.spark` 队列 ### 用 root 用户提交应用 在 `root` 用户下,执行下面命令: ``` yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 2 2 ``` 同时,在 `spark` 用户下,执行该命令 访问:http://hadoop2:8088/ ,如下图: [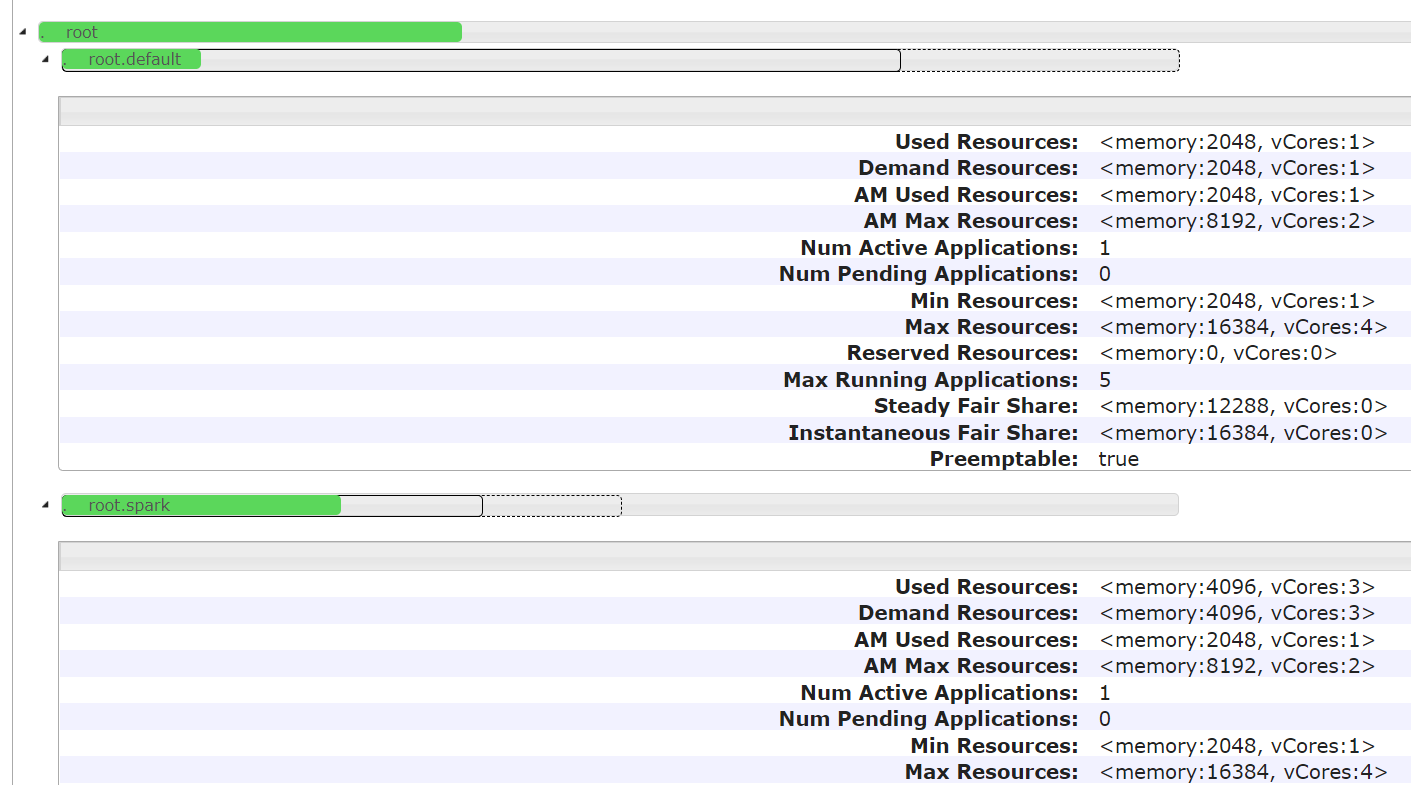](/upload/0/0/1IX4GRywMP7K.png) 2个应用同时执行,一个在 `root.default` 队列,一个在 `root.spark` 队列 原文出处:http://malaoshi.top/show_1IX2XOnbCeyW.html