数据结构:B+树 作者:马育民 • 2022-07-07 21:29 • 阅读:10124 # 为什么提出 B+树 ### B-树的缺点 所有中间结点,都存储 **数据指针** 和 **关键字**,导致可以存储在 B-树中的结点目数极大地减少了,从而增加 B-树的层数,进而增加了记录的搜索时间。 ### B+树 - B+树的 **中间节点没有数据**,所以同高度的B+树可以容纳更多的节点元素;在数据量相同的情况下,B+树的结构比B-树更加 **矮胖**,因此查询的IO次数也更少,查询效率更高; - B+树的查询必须最终查找到叶子节点,而B-树只要查找匹配的元素即可,无论匹配的元素处于中间节点还是叶子节点。 - B-树的查找性能并不稳定,非叶子节点也会存储数据,最好情况只查询根节点,最坏情况是查找叶子节点。而B+树的每一次查找都是稳定的,只有访问到叶子节点才能找到对应的数据。 **提示:**IO一次指从硬盘读数据,读取数据大小是固定的,非叶子节点不存储数据,可以容纳更多的节点元素,所以结构 **矮胖** # B+树的定义 B+树是B树的一种变形形式 **B+树上的叶子结点存储关键字** **叶子结点以上各层作为索引使用** 一棵 [m阶](https://www.malaoshi.top/show_1IX3dKTQtiJh.html "m阶") 的B+树定义如下: 1. 每个结点至多有 `m` 个子节点; 2. 除根结点外,每个结点至少有 `ceil(m/2)` 个子节点,根结点至少有两个子节点; 3. 有 `k` 个子节点的节点必有 `k` 个关键字 ### 例子 [](/upload/0/0/1IX3dnmhcfU9.png) 只有 **叶子节点保存数据**,其余中间节点仅用于索引 > **数据**:索引元素所指向的数据记录,比如数据库中的某一行 上面的这颗树中,得出结论: - 根节点元素 `8` 是子节点 `2,5,8` 的最大元素,也是叶子节点 `6,8` 的最大元素; - 根节点元素 `15` 是子节点 `11,15` 的最大元素,也是叶子节点`13,15` 的最大元素; - **根节点的最大元素也就是整个B+树的最大元素**,以后无论插入删除多少元素,始终要保持最大的元素在根节点当中。 - 由于父节点的关键字都出现在子节点中,**因此所有的叶子节点包含了全部关键字** - 相邻的叶子节点之间是通过链表指针连起来的,遍历叶子节点就能获取全部数据,如下图: [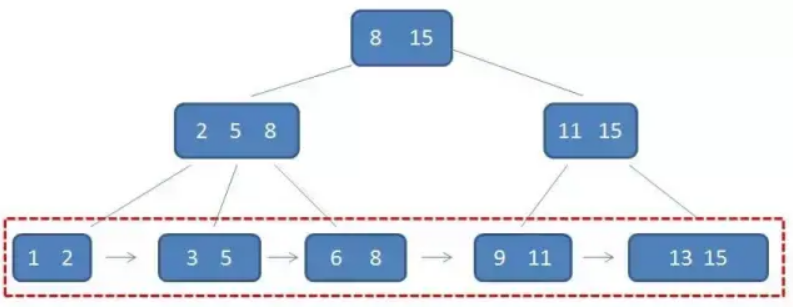](/upload/0/0/1IX3do50vSq3.png) # 查找 B+树的查找与B树不同,当索引部分某个结点的关键字与所查的关键字相等时,并不停止查找,应继续沿着这个关键字左边的指针向下,一直查到该关键字所在的叶子结点为止 比如我们要查找的元素是 `3` ### 第一次磁盘IO [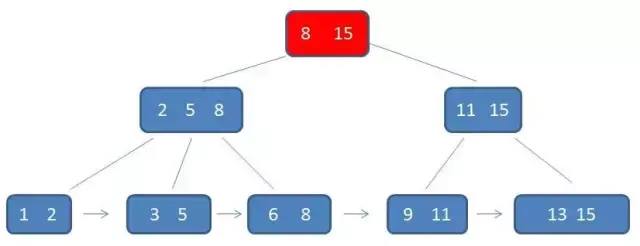](/upload/0/0/1IX3do6d31m8.png) ### 第二次磁盘IO [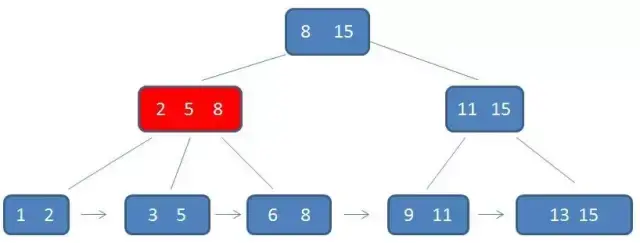](/upload/0/0/1IX3do6sWVPC.png) ### 第三次磁盘IO [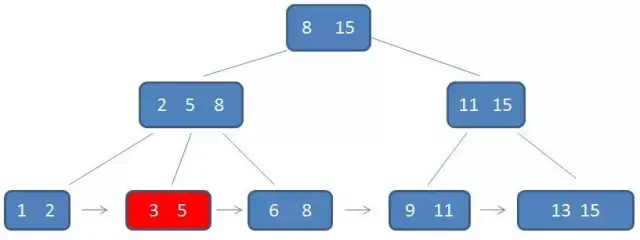](/upload/0/0/1IX3do7iBoDH.png) # 区间查询-案例 [](/upload/0/0/1IX3e6ItteZx.jpg) 通过案例,体验 B+树区间查询的优势:查询下面的 B-树中 `[21,63]` 之间的关键字 ### 第一步 访问根结点 `[59、97]` , 发现区间的左端点 `21` 小于 `59`, 则访问第一个左孩子 `[15、44、59]` [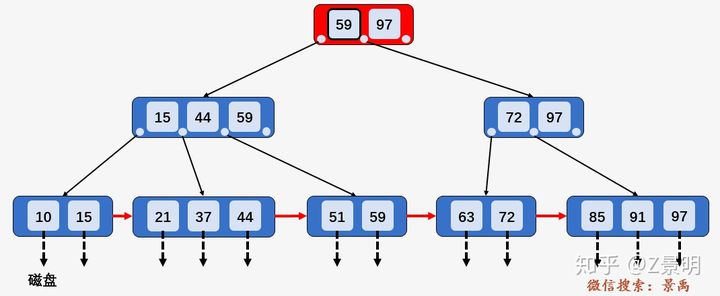](/upload/0/0/1IX3e6K1W6o4.jpg) ### 第二步 访问结点 `[15、44、59]` ,发现 `21` 大于 `15` 且小于 `44` ,则访问第二个孩子结点 `[21、37,44]` . [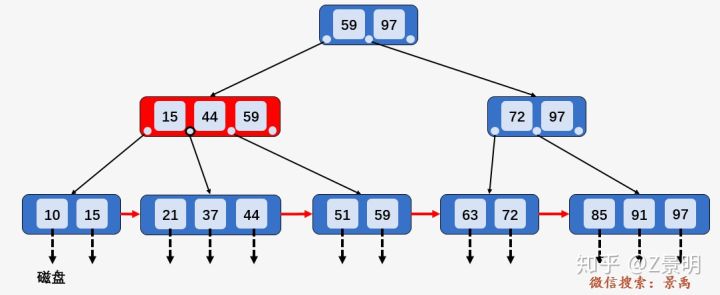](/upload/0/0/1IX3e6LaU9KF.jpg) ### 第三步 访问结点 `[21、37,44]` ,找到了左端点 `21` ,由于**相邻叶子节点通过链表指针连起来**,所以直接从左端点 `21` 开始一直遍历到左端点 `63` 即可,没有任何额外的磁盘 I/O 操作。 [](/upload/0/0/1IX3e6MFbHTI.jpg) # 使用场景 - MySQL数据库索引 # B+树 和 B-树的区别 - B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。 - B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。 - 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束 - B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。 #### 参考 https://baike.baidu.com/item/B%2B%E6%A0%91/7845683#9999 https://blog.csdn.net/jiang_wang01/article/details/113739230 https://zhuanlan.zhihu.com/p/149287061 原文出处:http://malaoshi.top/show_1IX3doDYCXUY.html