hbase2.1.x java PageFilter分页过滤器 作者:马育民 • 2023-01-22 09:59 • 阅读:10097 上接:[hbase2.1.x java 创建工程](https://www.malaoshi.top/show_1IX1wM13t84Y.html "hbase2.1.x java 创建工程") # 说明 `PageFilter` 分页过滤器,实现分页功能,效率比较低 # 实现 ### 创建分页过滤器对象 实现与 MySQL 分页不同,只能传入 **每页显示的记录数**,无法传入从哪行记录开始查询 ``` PageFilter filter = new PageFilter(pageSize); ``` ### 查询第一页 就是正常查询,不需要额外处理 [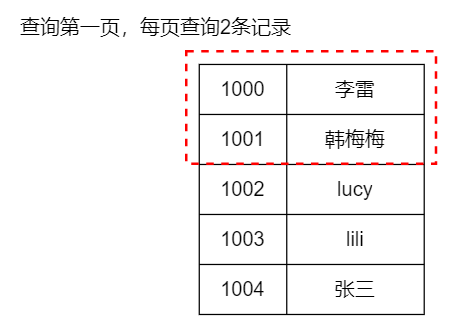](/upload/0/0/1IX4p9hvSb6M.png) ### 查询下一页 需要传递 `startRow`,才返回对应的 `pageSize` 行数据 > 这里的 `startRow`,相当于 mysql 中 `limit m,n` 中的 `m` **注意:**查询 **下一页** 时,需要传入 **上一页的最后一个** `rowkey`,并且不能包含该 `rowkey` [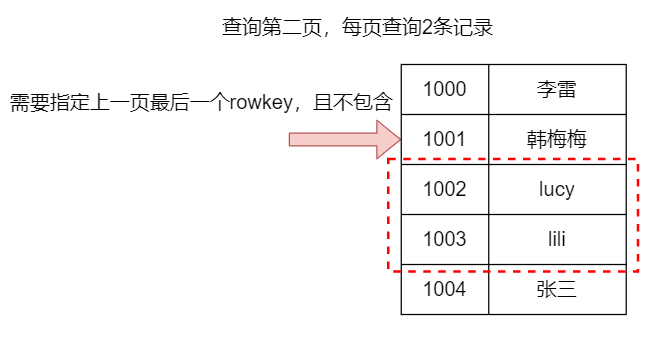](/upload/0/0/1IX4p9i6dbAP.png) 代码如下: ``` scan.withStartRow(Bytes.toBytes(rowKey),includeStartRow) ``` ### 返回数据 该过滤器并 **不能保证** 返回的行数小于等于指定的 `pageSize`,因为过滤器是分别作用到各个 `region server` 的,它只能保证当前 `region` 返回的结果行数不超过指定 `pageSize` ### 建议 分页时,需要过滤查询,最好通过 `rowkey` 过滤,不建议使用其他过滤器,效率太低 # 代码 在 [hbase2.1.x java 创建工程](https://www.malaoshi.top/show_1IX1wM13t84Y.html "hbase2.1.x java 创建工程") 类中,增加下面代码: ``` /** * 查询第一页 * @param tableName * @param family,返回指定的 family,指定null表示返回所有 * @param column,返回指定的 family、column,指定null表示返回所有 * @param startRow,指定开始的rowkey(包含)。如果不设置,则从表头开始 * @param includeStartRow,是否包含 startRow * @param stopRow,指定结束的rowkey(不包含)。如果不设置,则截止的末尾 * @param includeStopRow,是否包含 stopRow * @param pageSize,每页的记录数 * @return * @throws IOException */ protected List<CellData[]> pageFilter(String tableName, String family, String column,String startRow, boolean includeStartRow, String stopRow, boolean includeStopRow, int pageSize) throws IOException { this.tableName = tableName; this.family = family; this.column = column; this.lastRowKey = startRow; this.stopRow = stopRow; this.pageSize = pageSize; Table table = conn.getTable(TableName.valueOf(tableName)); //创建Scan Scan scan=new Scan(); // 返回指定的 family、column,不指定表示返回所有 if(column!=null && !"".equals(column)) { scan.addColumn(Bytes.toBytes(family), Bytes.toBytes(column)); } // 返回指定的 family,不指定表示返回所有 if(family!=null && !"".equals(family) && (column==null || "".equals(column))) { scan.addFamily(Bytes.toBytes(family)); } // 指定开始的行(包含)。如果不设置,则从表头开始 if(startRow!=null && !"".equals(startRow)) { scan.withStartRow(Bytes.toBytes(startRow),includeStartRow); } // 指定结束的行(不包含)。如果不设置,则截止的末尾 if(stopRow!=null && !"".equals(stopRow)) { scan.withStopRow(Bytes.toBytes(stopRow),includeStopRow); } PageFilter filter = new PageFilter(pageSize); scan.setFilter(filter); //执行scan ResultScanner resultScanner = table.getScanner(scan); Iterator<Result> iterator = resultScanner.iterator(); List<CellData[]> retList = new ArrayList<>(); //迭代,在迭代时,ResultScanner会发送get请求 while(iterator.hasNext()){ Result result=iterator.next(); //获取rowkey String rowkey=Bytes.toString(result.getRow()); // System.out.print(rowkey+"\t"); //获取所有单元格 List<Cell> list=result.listCells(); CellData[] arr = new CellData[list.size()]; int i = 0; for(Cell item:list){ String familyOfDb=Bytes.toString(CellUtil.cloneFamily(item)); String qualifier=Bytes.toString(CellUtil.cloneQualifier(item)); String valueDb=Bytes.toString(CellUtil.cloneValue(item)); CellData cellData = new CellData(familyOfDb,qualifier,rowkey,item.getTimestamp(),valueDb); arr[i] = cellData ; this.lastRowKey = rowkey; i ++ ; } retList.add(arr); } //用完要及时关闭,在迭代时,ResultScanner会发送get请求 resultScanner.close(); table.close(); return retList; } /** * 查询第一页 * @param tableName * @param family,返回指定的 family,指定null表示返回所有 * @param column,返回指定的 family、column,指定null表示返回所有 * @param startRow,指定开始的rowkey(包含)。如果不设置,则从表头开始 * @param stopRow,指定结束的rowkey(不包含)。如果不设置,则截止的末尾 * @param pageSize,每页的记录数 * @return * @throws IOException */ public List<CellData[]> getFirstPage(String tableName, String family, String column,String startRow,String stopRow, int pageSize) throws IOException { this.tableName = tableName; this.family = family; this.column = column; this.lastRowKey = startRow; this.stopRow = stopRow; this.pageSize = pageSize; return pageFilter(tableName, family, column,startRow,true,stopRow,false, pageSize); } /** * 查询下一页 * 关键:需要 传入上一页最后一个rowkey,并且不包含高rowkey。表示从该rowkey开始查询 * @return * @throws IOException */ public List<CellData[]> getNextPage() throws IOException { return pageFilter(tableName, family, column,lastRowKey,false,stopRow,false, pageSize); } ``` # 添加测试数据 创建表: ``` create "book","c1" ``` 清空表: ``` truncate 'book' ``` 添加数据: ``` put 'book','1001','c1:title','htlm从入门到放弃' put 'book','1001','c1:author','lucy' put 'book','1001','c1:price','097.50' put 'book','1002','c1:title','css从入门到放弃' put 'book','1002','c1:author','lili' put 'book','1002','c1:price','099.90' put 'book','1003','c1:title','hadoop从入门到放弃' put 'book','1003','c1:author','韩梅梅' put 'book','1003','c1:price','190.00' put 'book','1003','c1:title','hbase从入门到精通' put 'book','1003','c1:author','李雷' put 'book','1003','c1:price','029.50' ``` ### 测试 ``` public static void main(String[] args) throws IOException { HbaseUtils2_page utils=new HbaseUtils2_page(); utils.connect("hadoop1,hadoop2,hadoop3","2181"); // 查询第一页 List<CellData[]> resList = utils.getFirstPage("book", "c1", null, null,null,2); System.out.println("-----------第一页结果:"); String lastRowKey = ""; for(CellData[] arr : resList){ for(CellData item : arr){ System.out.println(item.getFamily()+":"+item.getRowkey()+":"+item.getQualifier() +" == "+item.getValue()); lastRowKey = item.getRowkey(); } System.out.println("----------"); } System.out.println("------------第二页结果:"); // 查询第二页,需要传入上一页的最后一个rowkey resList = utils.getNextPage(); for(CellData[] arr : resList){ for(CellData item : arr){ System.out.println(item.getFamily()+":"+item.getRowkey()+":"+item.getQualifier() +" == "+item.getValue()); } System.out.println("----------"); } utils.close(); } ``` 参考: https://blog.csdn.net/mxk4869/article/details/125614039 https://blog.csdn.net/m0_52602967/article/details/126144477 https://my.oschina.net/u/3346994/blog/1924013 https://blog.csdn.net/cpongo3/article/details/89327708 原文出处:http://malaoshi.top/show_1IX4p9j4dXAW.html